

Jak funguje VGG16 – neuronová síť pro extrakci obrazových prvků
A proč je užitečná pro každého, kdo pracuje s computer vision
Dnes se budeme věnovat architektuře neuronové sítě s názvem VGG16. Patří do rodiny konvolučních sítí, které tvoří základ moderních systémů počítačového vidění.
Začněme tedy analýzou konvolučních neuronů.
Jak funguje konvoluční neuronová síť: podrobné vysvětlení
Ačkoli první konvoluční neurony byly vytvořeny už v 90. letech, vyžadovaly velké množství trénovacích dat a velké výpočetní zdroje. Proto se předpokládá, že architekturu prvních konvolučních neuronových sítí vynalezl francouzský vědec Yann LeCun v roce 2012. Yann LeCun spatřil vícevrstvou strukturu v přírodě: síť kopíruje vizuální systém savců, včetně člověka.

Yann LeCun je autorem architektury prvních konvolučních neuronových sítí. Od roku 2013 pracuje jako Head of Facebook AI Research. // Photo by Jérémy Barande
Tady je příklad, jak to funguje. Předpokládejme, že neuronová síť má za úkol rozpoznat objekt na fotografii:
1. Konvoluční síť rozdělí obraz na malé části nazývané filtry nebo jádra.
2. Filtry se posouvají po obrázku a kontrolují, jak dobře odpovídají různým částem. Každý filtr se snaží najít specifické rysy objektu: okraje, barvy, textury.
3. Pokud filtr detekuje požadovaný rys, vytvoří aktivaci – vysokou hodnotu v určité oblasti obrazu.
4. Aktivace se kombinují dohromady a vytvářejí novou reprezentaci obrazu, přičemž vyšší úrovně abstrakce jsou reprezentovány hlubšími vrstvami sítě. Tímto způsobem konvoluční síť nezávisle analyzuje hierarchické rysy obrazů, od jednoduchých tvarů a čar až po složité objekty a pojmy.
5. Nakonec jsou zpracované funkce předány plně propojeným síťovým vrstvám pro klasifikaci nebo jiné úlohy, jako je detekce objektů nebo segmentace obrazu.


Konvoluční neuronové sítě výrazně zlepšily výkonnost systémů počítačového vidění: před jejich použitím bylo rozpoznávání úspěšné pouze v 25 % případů, zatímco v roce 2012 model AlexNet založený na konvolučních sítích vykazoval rozpoznávání v téměř 84 % případů.
Proto byly konvoluční sítě aktivně implementovány do softwaru pro analýzu lékařských obrazů, indexování a vyhledávání obrazů, automatické řízení vozidel na silnici atd.
Vlastnosti modelu VGG16
Přejděme k modelu VGG16. Zkratka VGG je zkratkou Visual Geometry Group, skupiny z Oxfordské univerzity, která tuto technologii vyvinula v roce 2013. Číslo 16 v názvu odkazuje na počet vrstev použitých v této neuronové síti: 13 konvolučních vrstev a 3 propojené vrstvy.
Podívejme se podrobněji na fungování VGG16:
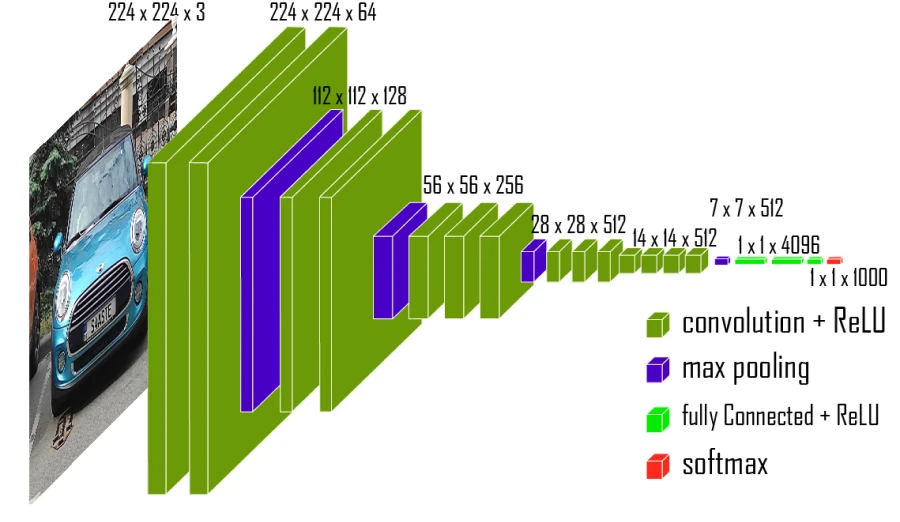
Jak funguje neuronová síť VGG16
Rozměr vstupní vrstvy neuronové sítě VGG16 je 224 × 224 pixelů. Úkolem vstupní vrstvy je převést vstupní data do formátu srozumitelného pro následující vrstvy neuronové sítě. To znamená, že je vstupním bodem, přes který jsou data přenášena do modelu ke zpracování.
To se stane, když obrázek projde vstupním bodem:
1. Data procházejí dvěma konvolučními vrstvami s aktivační funkcí ReLu a velikostí jádra 3 × 3 pixely.
2. Po dvou konvolučních vrstvách následuje vrstva MaxPooling, která snižuje dimenzionalitu dat na polovinu.
3. Následují dvě konvoluční vrstvy, které mají rovněž aktivační funkci ReLu a velikost jádra 3 × 3. Tyto vrstvy mají 128 filtrů. Potom se použije operace MaxPooling a velikost mapy příznaků se zase zmenší na polovinu.
4. Dále jsou tu tři konvoluční vrstvy s 256 filtry a tak dále.
S rostoucí hloubkou sítě se počet filtrů zvyšuje z 64 na 512. Za každou konvoluční vrstvou následuje aktivace ReLu, která pomáhá vnést do modelu nelinearitu. Nakonec po poslední vrstvě MaxPooling získáme rozměr 7 × 7 a 512 kanálů.
Data jsou přivedena na vstup plně propojené neuronové sítě, která obsahuje 4096 neuronů a má rovněž aktivační funkci ReLu (kromě poslední vrstvy Softmax). Protože síť byla původně trénována na tisíci různých třídách, výstupem je tisíc neuronů.
Důležité! Pokud použijeme dvě konvoluční vrstvy za sebou, získáme mapu prvků, která je analyzována druhou konvoluční vrstvou. Ukazuje se, že situace je podobná, jako kdybychom vzali jádro s rozměrem 5 × 5. Pokud však použijeme filtr s rozměrem 5 × 5, pak výpočtem počtu nastavitelných koeficientů zjistíme, že dvě konvoluční vrstvy jsou výhodnější než jedna s větším filtrem.
To se dá snadno vypočítat podle následujícího vzorce:
počet_nastavitelných_koeficientů = počet_filtrů *
(velikost_jádra_konvoluce * velikost_jádra_konvoluce + 1)
Pro jednu vrstvu bude výsledek 5*5+1=26 a pro dvě vrstvy 2(3*3+1)=20. To znamená, že počet nastavitelných koeficientů bude menší, ale zároveň bude rychlost trénování neuronové sítě vyšší.

Jak pracovat s VGG16
Pokud chceš začít pracovat s VGG16, potřebuješ framework pro hluboké učení. Například v jazyce Python. Můžeš použít např.:
1. TensorFlow
2. PyTorch
3. Keras
Seznam neobsahuje pouze tyto frameworky, ale právě tyhle poskytují vhodné nástroje pro vytváření, trénování a testování modelů neuronových sítí. Například PyTorch nabízí načtení už natrénovaného modelu z knihovny torchvision.models, Keras jej načítá z knihovny keras.applications a TensorFlow z knihovny tf.keras.applications.
Důležité! VGG16 jde najít taky v repozitářích s otevřeným zdrojovým kódem, například na GitHubu.
Pro kontrolu výkonu a přesnosti zpracování dat doporučujeme použít testovací datové sady, které obsahují obrázky odpovídající úlohám klasifikace objektů. Může se jednat o datové sady, jako jsou CIFAR-10, ImageNet nebo COCO.
Autor: Bondarenko Serhii


