

9 datových struktur, které budeš potřebovat
Matice, pole, stack a další
Datové struktury jsou konkrétní způsob uspořádání určitých dat v paměti počítače. Umožňují efektivní ukládání, načítání a manipulaci s informacemi a hrají klíčovou roli při optimalizaci výkonu softwaru a organizaci programového kódu.
V devadesátých letech navrhl Sungchun Moon, profesor na Korejské univerzitě pokročilých technologií, aby Bill Gates pojmenoval svůj startup Microdata místo Microsoft. Moon poukázal na to, že data a jejich struktura jsou budoucností programování.
Povězme si o datových strukturách, které se používají nejčastěji.
1. Pole (Array)
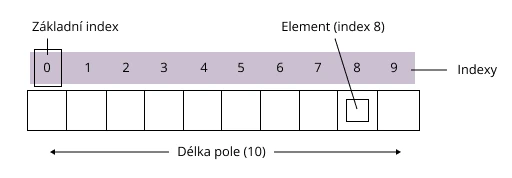
Pole je jednoduchá základní struktura. Od polí jsou odvozeny zásobníky (stacks), fronty a seznamy. Jednotce dat v poli je přiřazeno číslo nebo index, který označuje její umístění. Když chceš najít buňku s informací v poli, musíš její index přičíst k základnímu prvku. Základní prvek je obvykle označen názvem samotného pole.
Představ si zápisník se stránkami očíslovanými od 1 do 10. Každá z nich může obsahovat informace nebo být prázdná. Zápisník je pole stránek, stránky jsou prvky pole „zápisník“. Programově získáš informace ze stránky odkazem na její index, tj. příkaz „zápisník+4“ bude odkazovat na obsah čtvrté stránky.
Pole je pevná struktura ukládající prvky stejného typu v souvislých paměťových buňkách. Existuje výjimka – heterogenní pole, která mohou uchovávat data různých typů. Pole se vyrábějí jednorozměrná a vícerozměrná (pole v poli). Jejich velikost je pevně daná, takže do již vytvořeného pole nelze jednoduše vložit nový prvek. Staré pole musíš zkopírovat a vytvořit nové, čímž se zvětší jeho velikost.
2. Matice (Matrix)
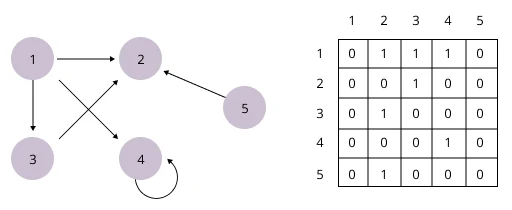
Matice je dvourozměrné pole, které vypadá jako seznam sloupců a řádků s datovými položkami v průsečíku. Je to obdélníkové pole, u kterého počet řádků a sloupců určuje jeho velikost. V matematice se používají ke kompaktnímu zápisu lineárních algebraických nebo diferenciálních rovnic.
Matrice se používají k popisu pravděpodobností. Například k hodnocení stránek ve vyhledávači Google pomocí algoritmu PageRank. V počítačové grafice – pro práci s 3D modely a jejich promítání na 2D obrazovku.
3. Propojený seznam (Linked list)
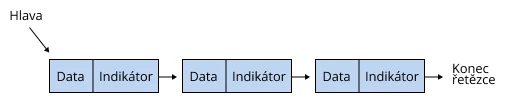
Seznamy jsou podobné polím, ale mají flexibilnější strukturu. Vypadají jako řetězce uzlů, kde každý uzel obsahuje odkaz na další uzel. K prvkům v propojeném seznamu se přistupuje postupně, na rozdíl od polí s náhodným přístupem. Seznamy se vyrábějí v jednovazbových a dvouvazbových strukturách.
Počáteční prvek této struktury se nazývá hlava a všechny následující uzly řetězce se nazývají chvost. Chvost se skládá z prvků dvou typů: s informacemi (info) a s označením dalšího uzlu (next). Konec řetězce je označen jako null.
4. Zásobník (Stack)
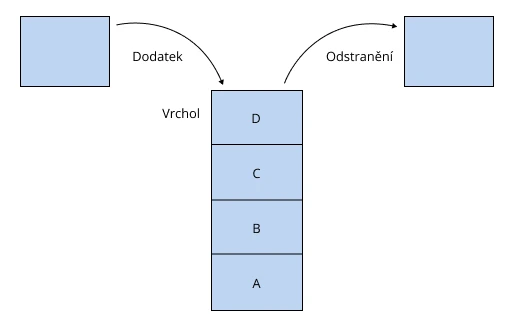
Jedná se o vertikální sloupec s bloky, které jsou přístupné pouze z jednoho konce: shora nebo zdola. Je to jako hromada knih – aby ses dostal*a k těm dole, musíš nejprve odstranit všechny nad nimi.
Nové prvky stacku nahradí staré. Principem takové struktury je LIFO (last in – first out). Proto se stack nazývá také zásobník – analogicky ke střelné zbrani: vystřelí se náboj, který byl nabitý jako poslední.
Tato datová struktura je implementována ve funkci undo. Program ukládá stav operace tak, aby se poslední akce stala první ve frontě undo. V stacku jsou možné pouze tři operace: přidání prvku (push), odstranění (pop), čtení (peek).
Stack může být implementován jako spojový seznam nebo jednorozměrné pole. V prvním případě každý prvek obsahuje odkaz na další prvek, v druhém případě je uspořádán podle indexu.
Existuje podobná datová struktura – deque (deque – double ended queue, „dvoucestná fronta“). Jedná se o stack s obousměrným přístupem.
související kurzy:
Raspberry Pi: Vytvářej chytrá zařízení
David Šafrata
Software Engineer & Cybersecurity Consultant

5. Fronta (Queue)
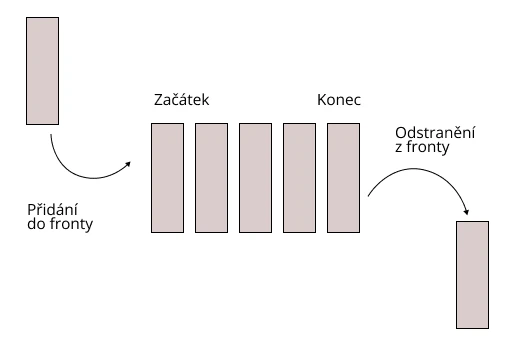
Tento typ datové struktury se podobá stackům, ale princip fungování je realizován jako FIFO (first in – first out). Je to jako v supermarketu: první, kdo si odnese nákup domů je ten, kdo se postaví dřív do fronty.
Fronty se používají, když je třeba rozdělit prostředek mezi více uživatelů (práce procesoru, šířka pásma směrovače). Nebo když jsou data přenášena asynchronně, tj. rychlost příjmu a odesílání se liší.
V této datové struktuře lze provádět dvě operace: přidání prvku na konec fronty (enqueue) a odstranění prvního prvku (dequeue). Fronty mohou mít podobu spojových seznamů nebo polí, podobně jako stacky.
6. Strom (Tree)
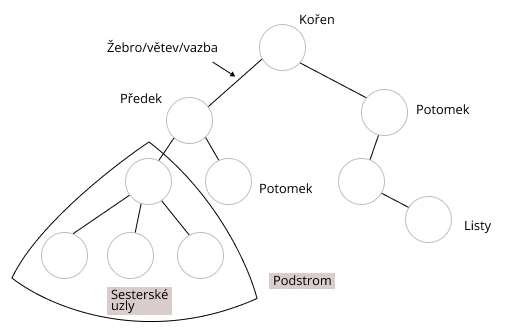
Stromy jsou struktura, ve které jsou data propojena uzly a hierarchicky uspořádána. Existují binární vyhledávací stromy, rozšířené stromy, černo-červené stromy a desítky dalších typů.
Stejně jako skutečný strom má kořeny, větve a listy. Nejvyšší uzel této datové struktury, který nemá žádné předky, se nazývá kořenový uzel. Ostatní uzly se nazývají potomci nebo děti. Dceřiné uzly se stejným rodičem jsou sourozenecké uzly. A listy jsou uzly, které nemají žádné potomky.
Stromy se používají například při vývoji videoher. Umožňují rozdělit prostor a rychle najít objekty. Například strom se čtyřmi podřízenými uzly (quadtree) – kvadrant – slouží k vytvoření mapy a orientaci na čtyřech stranách světa ve hře.
Stromy se ale obtížně ukládají a mají nízkou rychlost.

7. Halda (Heap)
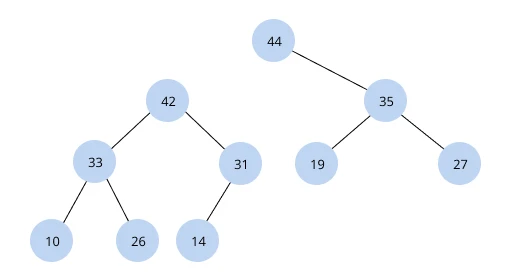
Haldy jsou téměř stejné jako stromy: také mají kořenové a podřízené uzly. Liší se ale systémem hierarchie: haldy jsou dvojího druhu – ty, kde jsou hodnoty kořenových uzlů menší, a ty, kde jsou hodnoty větší než hodnoty podřízených uzlů. Tyto datové struktury mohou být uloženy v jednoduchém nebo dynamickém poli, což znamená, že zabírají mnohem méně místa než stromy.
Při přidávání nové položky na haldu je třeba zkontrolovat všechny ostatní položky. Prvky jsou seřazeny sestupně, od velkých po malé.
Haldy se používají k třídění objektů nebo k implementaci prioritních front.

8. Prefixový strom (Prefix tree)
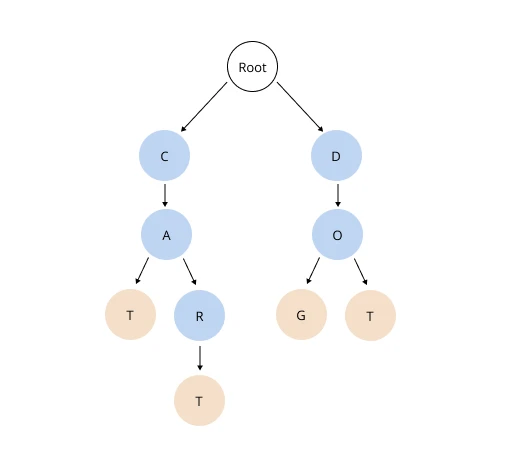
Při použití automatického dokončování se spustí datová struktura zvaná prefixový strom. Jedná se o typ vyhledávacího stromu, který se používá například k ukládání slov a jejich @rychlému prohledávání. Uzly tohoto stromu se nazývají štítky.
Každý štítek obsahuje jedno písmeno a vyhledávání probíhá postupně přes štítky. Když se pořadí písmen začne lišit, strom se rozvětví. Představ si, jak chytrý telefon navrhuje celé slovo, když napíšeme několik písmen.
Prefixový strom se používá v NLP a při syntaktické analýze přirozených jazyků.
9. Hashovací tabulka (Hash table)
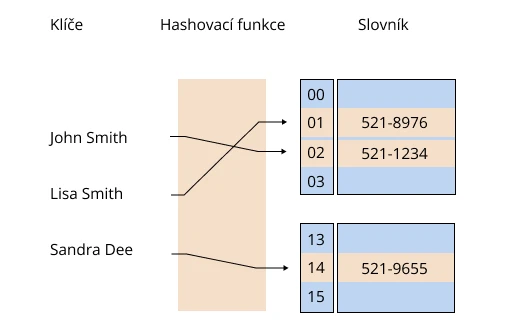
Hashovací tabulka je datová struktura, která uchovává hodnoty a k nim přiřazené klíče. Představte si velkou knihovnu. Obvykle potřebuješ referenční knihu, abys v ní našel*našla nějakou knihu.
Můžeš ale použít hashovací algoritmus – pak ti funkce okamžitě poskytne číslo skříně a umístění knihy v ní, a to díky klíčům. Ty obsahují informace pro přístup k souboru a jeho umístění. Hashování se používá v kryptografii k šifrování informací.
Hashovací funkce redukuje dlouhý řetězec znaků na krátkou hodnotu. Ta bude klíčem nebo indexem datové položky v hashovací tabulce. Soubor dat v ní se nazývá slovník.
Výkonnost hashovací tabulky závisí na hashovací funkci, velikosti tabulky a způsobu ošetření kolizí.
Použité zdroje: GeeksforGeeks, freeCodeCamp, Towards Data Science a výzkum Alfreda Aho, Johna Hopcrofta a Jeffreyho Ullmana.
Autor: Nadia Osmokescu


